MLP
O MLP constitui uma arquitetura de rede neural artificial feed-forward composta por múltiplas camadas de neurônios artificiais. A camada de entrada recebe os features do problema (idade, renda, histórico creditício), as camadas ocultas processam essas informações através de funções de ativação não-lineares (ReLU, sigmoid, tanh), e a camada de saída produz a classificação final. O aprendizado ocorre via algoritmo de backpropagation, que ajusta iterativamente os pesos das conexões baseado no erro de predição calculado através de gradient descent.
Vantagens
- Capacidade de modelagem não-linear: Excelente habilidade para capturar padrões complexos e interações não-triviais entre variáveis.
- Versatilidade de aplicação: Adaptável a diversos tipos de problemas, incluindo classificação multiclasse, regressão e previsão de séries temporais.
- Aproximação universal: Teoricamente capaz de aproximar qualquer função contínua com arquitetura adequada.
- Escalabilidade: Performance melhora com o aumento do volume de dados de treinamento.
Desvantagens
- Intensidade computacional: Requer recursos computacionais substanciais, frequentemente necessitando GPUs para treinamento eficiente.
- Complexidade de configuração: Demanda ajuste cuidadoso de arquitetura (número de camadas e neurônios), taxa de aprendizado, regularização e outras configurações.
- Propensão ao overfitting: Especialmente problemático em datasets pequenos, onde a rede pode memorizar padrões específicos sem generalizar adequadamente.
- Interpretabilidade limitada: Funciona como uma "caixa preta", dificultando a compreensão dos fatores que influenciam decisões específicas.
Métricas
| Métrica | Valor |
|---|---|
| Acurácia | 0.9002 |
| Recall | 0.8170 |
| Especificidade | 0.9359 |
| Precisão | 0.9227 |
| F1-Score | 0.9292 |
| Tempo de Treino | 783.83s |
Matriz de Confusão
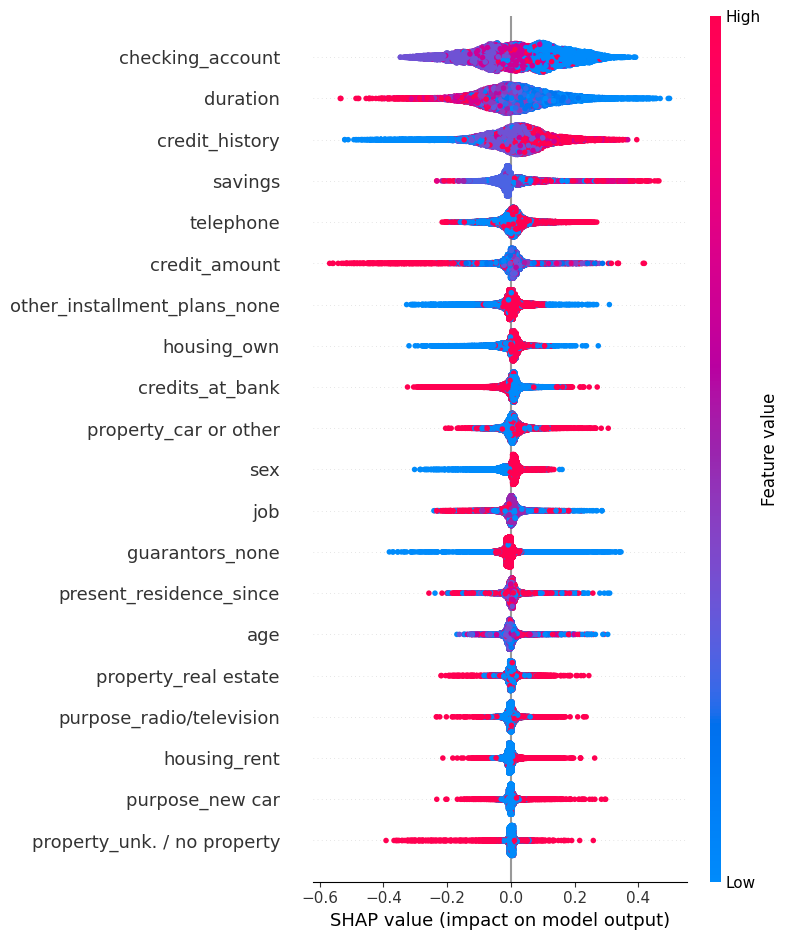
Feature Importance
O que é este gráfico?
O gráfico de summary do SHAP mostra a importância média das features para o modelo. Cada ponto representa uma observação e sua contribuição para a predição; pontos à direita aumentam a probabilidade da classe positiva, enquanto pontos à esquerda diminuem.
As cores normalmente representam o valor da feature (alto/baixo). Este gráfico dá uma visão global da importância e direção do efeito das variáveis.