Regressão Logística
A Regressão Logística é um modelo estatístico fundamental para problemas de classificação binária e multiclasse. O algoritmo utiliza uma combinação linear das variáveis independentes, aplicando posteriormente a função sigmoide para transformar o resultado em probabilidades no intervalo [0,1]. No contexto de concessão de crédito, essa probabilidade representa a chance de um cliente ser classificado como "bom pagador" ou "mau pagador". O modelo otimiza seus coeficientes através do método da máxima verossimilhança, minimizando sistematicamente a divergência entre previsões e valores observados.
Vantagens
- Interpretabilidade superior: Os coeficientes fornecem insights claros sobre a influência de cada variável, permitindo compreender como fatores como renda, histórico creditício e tempo de emprego impactam a decisão de crédito.
- Eficiência computacional: Algoritmo de treinamento rápido, adequado para processamento de grandes volumes de dados com recursos computacionais limitados.
- Saídas probabilísticas: Além da classificação binária, fornece probabilidades associadas às previsões, facilitando a calibração de políticas de risco e definição de pontos de corte.
- Estabilidade: Menos propenso a overfitting em comparação com algoritmos mais complexos.
Desvantagens
- Limitação de linearidade: Assume relação linear entre variáveis independentes e o logit da variável dependente, restringindo sua aplicação em cenários com interações complexas.
- Performance limitada em dados não-lineares: Pode apresentar acurácia inferior quando padrões de comportamento apresentam relações não-lineares complexas.
- Sensibilidade a outliers: Valores extremos podem distorcer significativamente os coeficientes do modelo.
- Necessidade de pré-processamento: Requer tratamento cuidadoso de variáveis categóricas e normalização de features numéricas.
Métricas
| Métrica | Valor |
|---|---|
| Acurácia | 0.7256 |
| Recall | 0.2779 |
| Especificidade | 0.9175 |
| Precisão | 0.7477 |
| F1-Score | 0.8240 |
| Tempo de Treino | 20.58s |
Matriz de Confusão
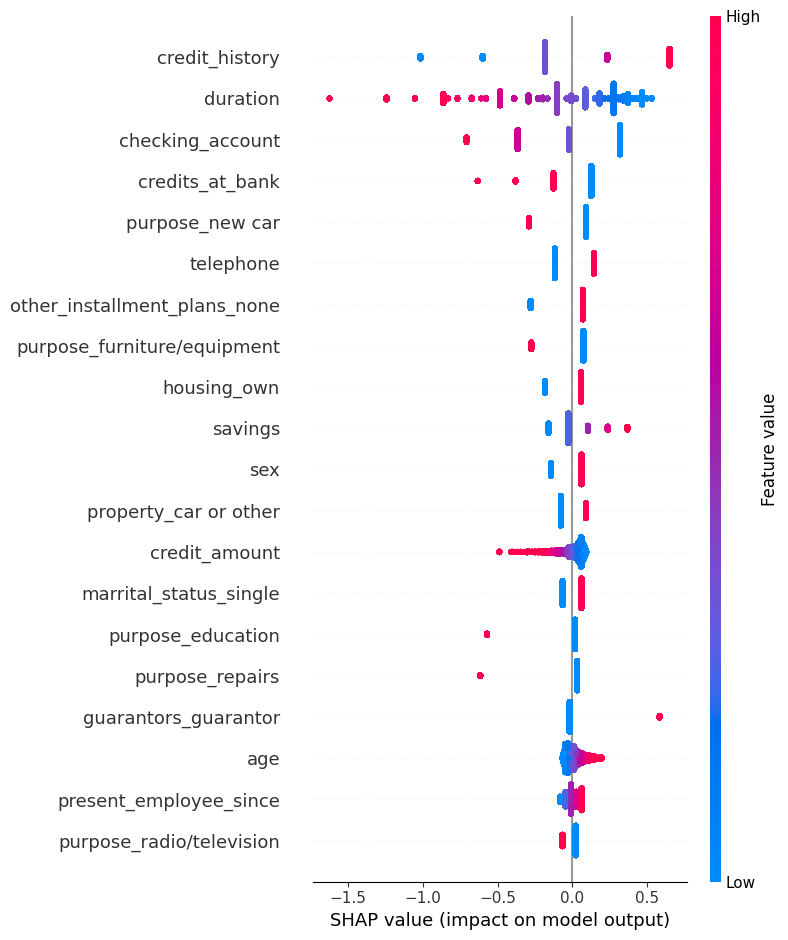
Feature Importance
O que é este gráfico?
O gráfico de summary do SHAP mostra a importância média das features para o modelo. Cada ponto representa uma observação e sua contribuição para a predição; pontos à direita aumentam a probabilidade da classe positiva, enquanto pontos à esquerda diminuem.
As cores normalmente representam o valor da feature (alto/baixo). Este gráfico dá uma visão global da importância e direção do efeito das variáveis.