XGBoost
O XGBoost (Extreme Gradient Boosting) é uma implementação do algoritmo de gradient boosting, que constrói árvores de decisão de forma sequencial, em que cada nova árvore é treinada para corrigir os erros residuais das anteriores, ajustando o modelo por meio do gradiente descendente aplicado a uma função de perda. Diferencia-se por incorporar mecanismos avançados de regularização (L1 e L2), que ajudam a controlar a complexidade e evitar o overfitting, além de um processo de pruning inteligente que elimina divisões pouco relevantes.
Vantagens
- Performance superior: Frequentemente alcança os melhores resultados em métricas como AUC-ROC, precisão e F1-score em problemas de classificação de crédito.
- Otimização avançada: Implementa técnicas sofisticadas de otimização, incluindo second-order approximation e column block for parallel learning.
- Flexibilidade de configuração: Oferece extensa gama de hiperparâmetros para ajuste fino, permitindo adaptação a diferentes características dos dados.
- Tratamento de missing values: Manuseia automaticamente valores ausentes através de algoritmos de split inteligente.
Desvantagens
- Complexidade de Tuning: Requer expertise técnica considerável para otimização adequada dos hiperparâmetros e prevenção de overfitting.
- Demanda computacional: Alto consumo de memória e processamento, especialmente em datasets grandes com muitas iterações.
- Interpretabilidade desafiadora: Embora existam ferramentas como SHAP values, explicar decisões individuais permanece complexo.
- Sensibilidade a ruído: Pode ser propenso a overfitting em dados com alta dimensionalidade e ruído significativo.
Métricas
| Métrica | Valor |
|---|---|
| Acurácia | 0.9127 |
| Recall | 0.8457 |
| Especificidade | 0.9414 |
| Precisão | 0.9344 |
| F1-Score | 0.9378 |
| Tempo de Treino | 37.35s |
Matriz de Confusão
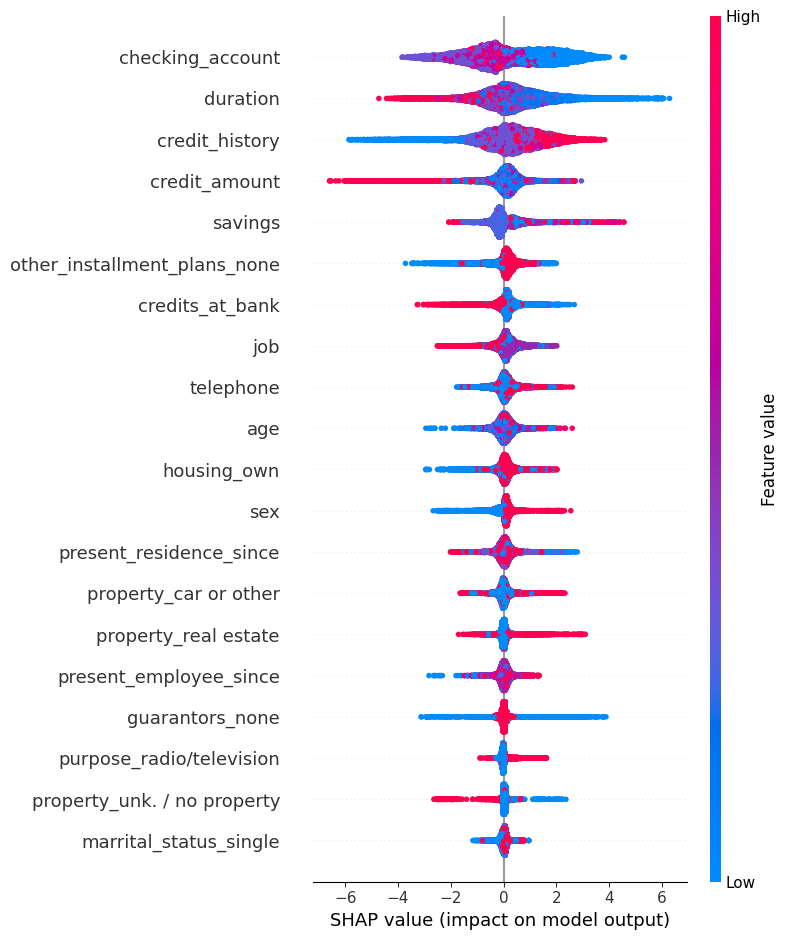
Feature Importance
O que é este gráfico?
O gráfico de summary do SHAP mostra a importância média das features para o modelo. Cada ponto representa uma observação e sua contribuição para a predição; pontos à direita aumentam a probabilidade da classe positiva, enquanto pontos à esquerda diminuem.
As cores normalmente representam o valor da feature (alto/baixo). Este gráfico dá uma visão global da importância e direção do efeito das variáveis.