Random Forest
O Random Forest implementa o conceito de ensemble learning através da técnica de bagging (bootstrap aggregating). O algoritmo constrói múltiplas árvores de decisão utilizando subconjuntos aleatórios dos dados de treinamento, combinando suas previsões através de votação majoritária (classificação) ou média (regressão). A aleatoriedade é introduzida tanto na seleção de amostras quanto na escolha de subconjuntos de features para cada divisão, reduzindo a correlação entre árvores individuais.
Vantagens
- Robustez ao Overfitting: A combinação de múltiplas árvores reduz significativamente a variância do modelo, melhorando a capacidade de generalização.
- Análise de Importância de Features: Fornece métricas quantitativas sobre a relevância de cada variável no processo decisório, auxiliando na seleção de features e interpretação de resultados.
- Versatilidade: Manuseia eficientemente dados tabulares heterogêneos, incluindo variáveis numéricas e categóricas, com tratamento nativo de valores ausentes
- Paralelização Natural: O treinamento de árvores individuais pode ser paralelizado, reduzindo o tempo de processamento
Desvantagens
- Complexidade Computacional: Demanda recursos significativos de memória e processamento, especialmente com grandes volumes de dados e muitas árvores
- Interpretabilidade Limitada: A natureza ensemble dificulta a compreensão intuitiva das regras de decisão, ao contrário de uma árvore de decisão única
- Latência de Predição: Tempo de resposta mais elevado em produção devido à necessidade de agregação de múltiplas previsões
- Tendência a Overfitting em Ruído: Embora mais robusto que árvores individuais, ainda pode capturar padrões espúrios em datasets com muito ruído
Métricas
| Métrica | Valor |
|---|---|
| Acurácia | 0.9068 |
| Recall | 0.8366 |
| Especificidade | 0.9369 |
| Precisão | 0.9304 |
| F1-Score | 0.9336 |
| Tempo de Treino | 73.88s |
Matriz de Confusão
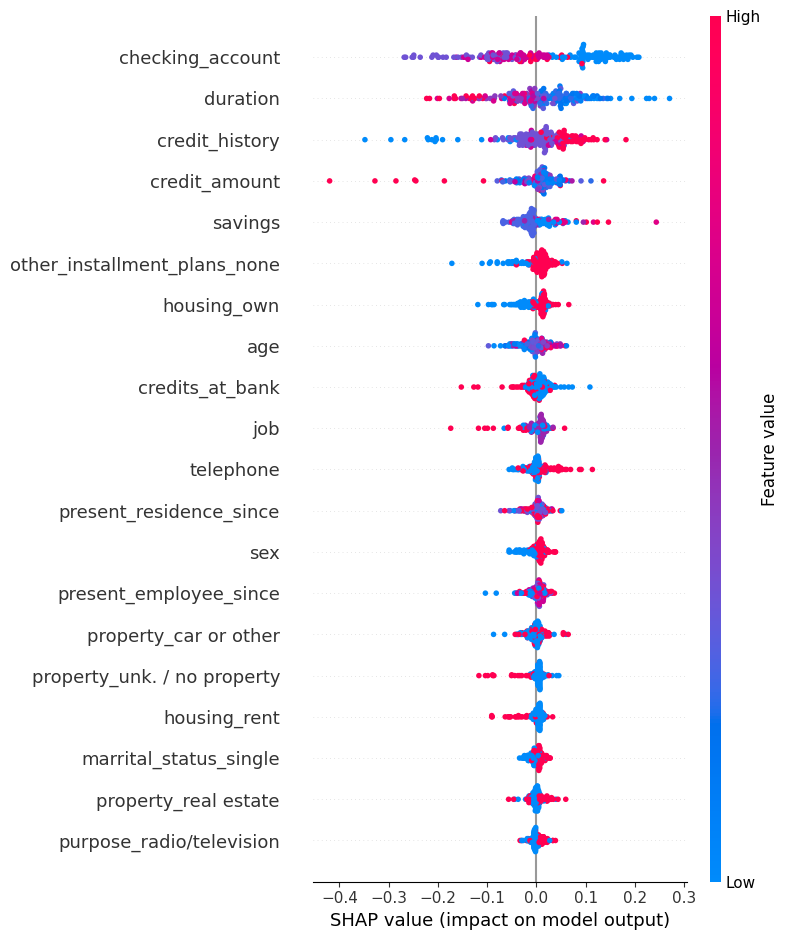
Feature Importance
O que é este gráfico?
O gráfico de summary do SHAP mostra a importância média das features para o modelo. Cada ponto representa uma observação e sua contribuição para a predição; pontos à direita aumentam a probabilidade da classe positiva, enquanto pontos à esquerda diminuem.
As cores normalmente representam o valor da feature (alto/baixo). Este gráfico dá uma visão global da importância e direção do efeito das variáveis.